《实战AI大模型》部署大模型-第06节:基于Ollama+OpenWebUI和DeepSeek-R1本地部署AI对话系统
作者:冰河
星球:http://m6z.cn/6aeFbs
博客:https://binghe.site
文章汇总:https://binghe.site/md/all/all.html
源码获取地址:https://t.zsxq.com/0dhvFs5oR
大家好,我是冰河~~
随着数据安全与隐私保护意识的提升,越来越多开发者和企业开始关注将AI能力部署在本地的方案。与依赖云服务的传统方式相比,本地部署不仅能有效避免敏感数据外泄的风险,还能减少网络延迟,提供更高的定制灵活性。本章,将分享如何通过 Ollama 与 OpenWebUI 这两款工具的搭配,在本地环境中快速搭建并运行 DeepSeek-R1 大模型,实现从环境准备到实际应用的全流程覆盖。
一、核心工具与模型介绍
Ollama:轻量高效的模型运行引擎
Ollama 是一个专为本地运行大语言模型而设计的工具,它让模型的下载、管理和使用变得异常简单。即使你没有高性能的GPU,也能通过CPU模式顺利运行多种主流开源模型。它支持跨平台操作,无论是Windows、macOS还是Linux系统,都能通过命令行轻松驾驭。
OpenWebUI:直观友好的交互界面
如果你习惯了ChatGPT那样的网页对话体验,那么OpenWebUI绝对会让你感到亲切。它提供了一个功能完整的Web界面,支持多模型切换、对话历史记录、Markdown渲染等实用功能。更重要的是,它完全开源,支持Docker部署,还具备插件扩展能力。
DeepSeek-R1:实力不俗的国产大模型
DeepSeek-R1 是由深度求索公司推出的多模态大语言模型,在代码生成、逻辑推理和中英文翻译等方面表现突出。该模型提供了从7B到72B等多个参数版本,大家可以根据自己的硬件配置和任务需求灵活选择。无论是构建企业知识库、自动化脚本编写,还是生成数据分析报告,它都能胜任。
二、部署前的环境准备
在开始部署之前,请确保你的设备满足以下要求:
操作系统:Windows 10及以上版本、macOS 12及以上版本,或Ubuntu 20.04及以上版本。
硬件配置建议:
- 运行7B/8B模型:至少需要8GB内存和4GB显存(NVIDIA GTX 1060或同等级别显卡)
- 运行32B模型:推荐24GB显存(如RTX 4090)
- 运行671B完整版模型:需要专业级显卡(如NVIDIA A100)集群支持
网络环境:由于需要从GitHub和Docker Hub下载资源,建议提前配置好网络代理或国内镜像加速服务。
三、详细部署步骤
第一步:安装Ollama
下载与安装:
- Linux系统用户,只需在终端中执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh
- Windows系统用户,直接访问 Ollama官网 下载安装程序。
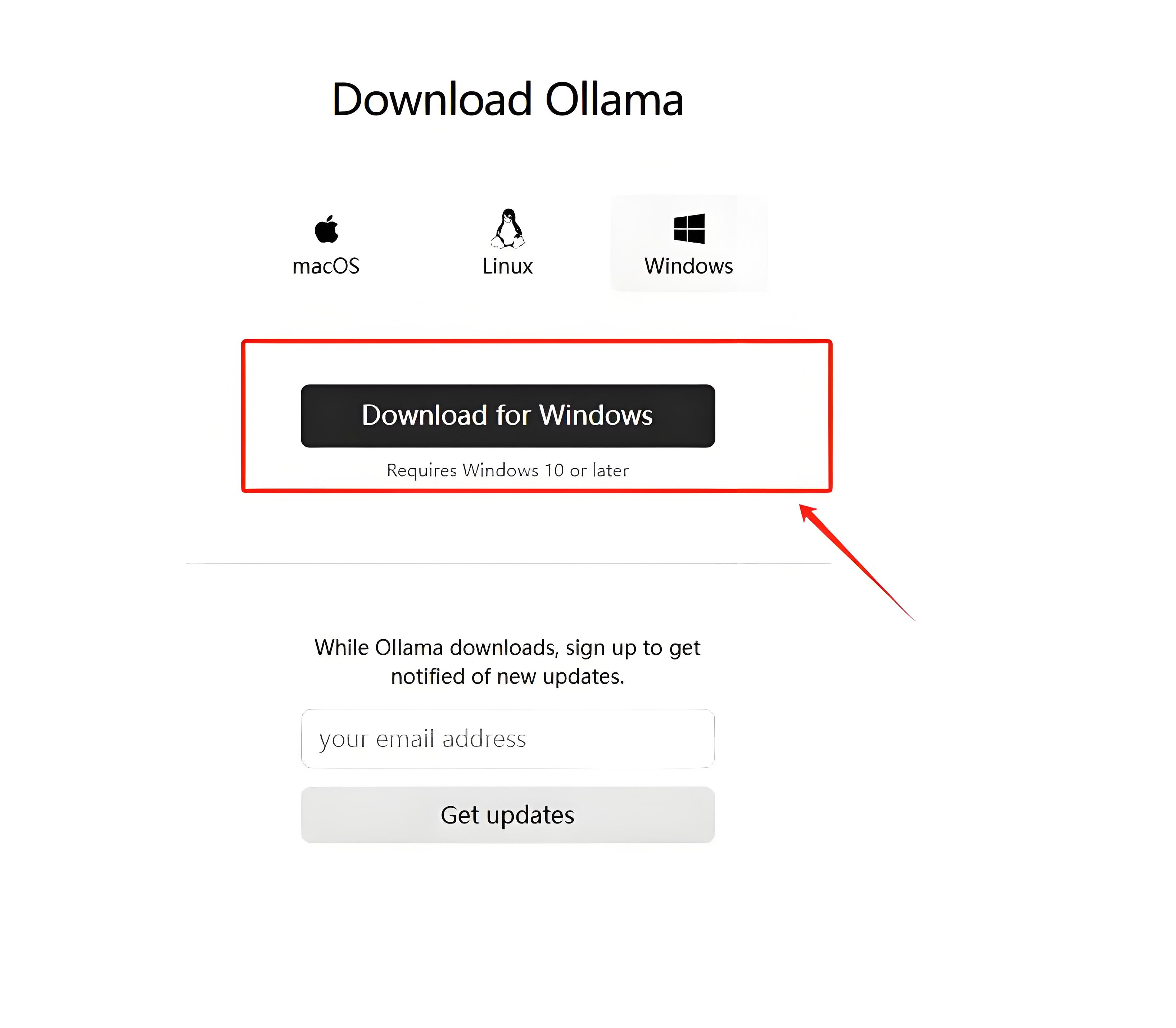
验证安装结果: 安装完成后,在命令行中输入:
ollama --version
如果正确显示版本号(如0.1.25),说明安装成功。
环境变量配置(可选但推荐):
- 设置
OLLAMA_MODELS变量来指定模型文件的存储位置,例如指向一个空间充足的分区。 - 设置
OLLAMA_HOST为0.0.0.0,方便在同一网络下的其他设备访问。 - 如需了解更多配置选项,可参考Ollama的GitHub仓库。
第二步:获取DeepSeek-R1模型
模型选择建议:
- 如果你是初次尝试或硬件配置有限,建议从
deepseek-r1:7b(4.7GB)或deepseek-r1:8b(4.9GB)开始。 - 如果需要处理更复杂的任务且有足够硬件支持,可以考虑
deepseek-r1:32b(20GB)或deepseek-r1:70b(43GB)版本。
下载模型: 在命令行中执行:
# 下载并运行7B模型
ollama run deepseek-r1:7b
# 或者下载8B模型
ollama run deepseek-r1:8b
验证模型运行状态: 当看到终端中出现类似下面的交互界面时,说明模型已成功加载:
查看完整文章
加入冰河技术知识星球,解锁完整技术文章、小册、视频与完整代码
