# 《RPC手撸专栏》第29章:基于SPI扩展FST序列化与反序列化机制
作者:冰河
星球:http://m6z.cn/6aeFbs (opens new window)
博客:https://binghe.site (opens new window)
文章汇总:https://binghe.site/md/all/all.html (opens new window)
沉淀,成长,突破,帮助他人,成就自我。
大家好,我是冰河~~
在前面的章节中,我们实现了对标Dubbo的SPI基础功能,并基于SPI扩展了JDK、Json与Hessian2的序列化与反序列化方式,就序列化模块而言,整体具备了高度的可扩展性。来吧,我们进一步扩展序列化与反序列化机制。
# 一、前言
这次又要怎么扩展呢?
在前面的章节中,在涉及到数据的编解码过程中,我们实现了基于SPI扩展JDK、Json与Hessian2的序列化与反序列化方式。这次我还想继续扩展序列化与反序列化的类型,怎么办呢?
还能怎么办呢?撸起袖子加油干吧!
# 二、目标
目标很明确:新增FST序列化与反序列化方式!
JDK自带的序列化与反序列化方式存在着诸多的弊端,其中最为严重的就是性能不足和序列化后的字节体积较大,这两个弊端对于网络应用来说,是非常致命的,序列化带来的应用延迟和序列化的数据体积较大造成网络传输延迟,内存消耗较高等问题,会直接导致网络应用性能的低下。
FST序列化全称是Fast Serialization,它是对JDK自带的序列化的替换实现。JDK序列化的两点弊端,在FST中得到了较大的改善,FST的特征如下:
- 比JDK提供的序列化性能提升了10倍。
- 序列化后的体积是JDK序列化的1/4~1/3。
- 支持堆外Map,和堆外Map的持久化。
- 支持序列化为JSON。
大名鼎鼎的Dubbo,内部就支持FST的序列化与反序列化方式。
来吧,这章,我们就基于SPI扩展支持FST序列化与反序列化机制。
# 三、设计
如果让你设计基于SPI扩展FST序列化与反序列化,你会怎么设计呢?
基于SPI再次扩展FST的序列化与反序列化机制后,整体流程如图29-1所示。
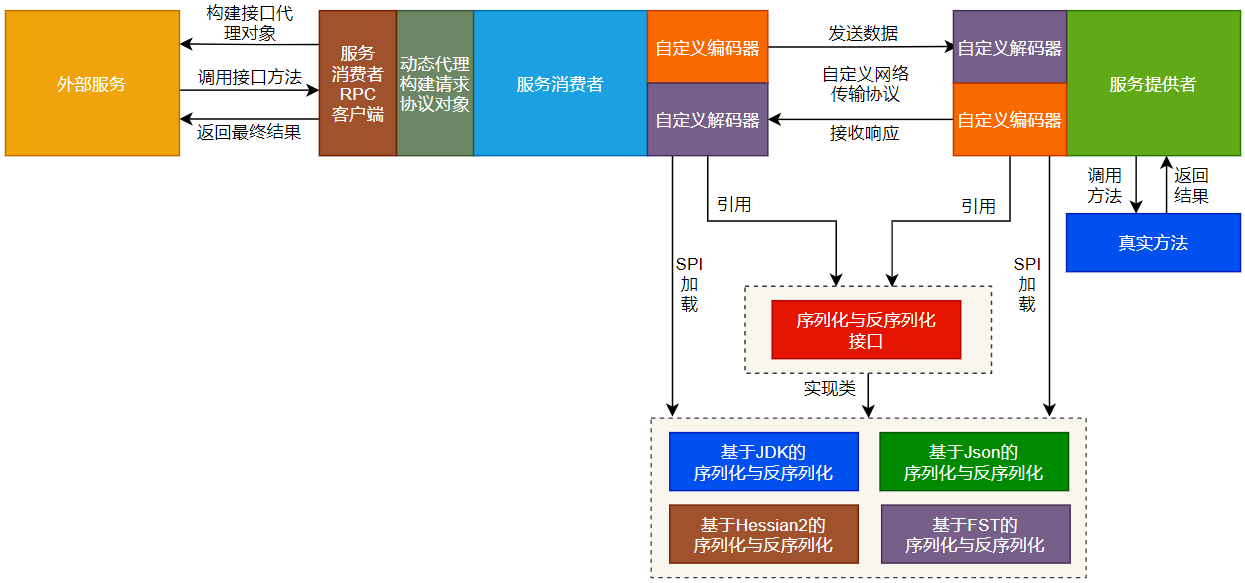
由图29-1可以看出,在实现数据的编解码过程中,再次扩展基于FST的序列化和反序列化方式后,自定义的编解码器会通过SPI机制加载序列化与反序列化的具体实现方式,程序会根据具体需要加载某一种特定的序列化与反序列化方式,同样不会在程序中硬编码写死。
- 基于JDK的序列化与反序列化方式的Key为jdk。
- 基于Json的序列化与反序列化方式的Key为json。
- 基于Hessian2的序列化与反序列化方式的Key为hessian2。
- 基于FST的序列化与反序列化方式的Key为fst。
# 四、实现
说了这么多,具体要怎么实现呢?
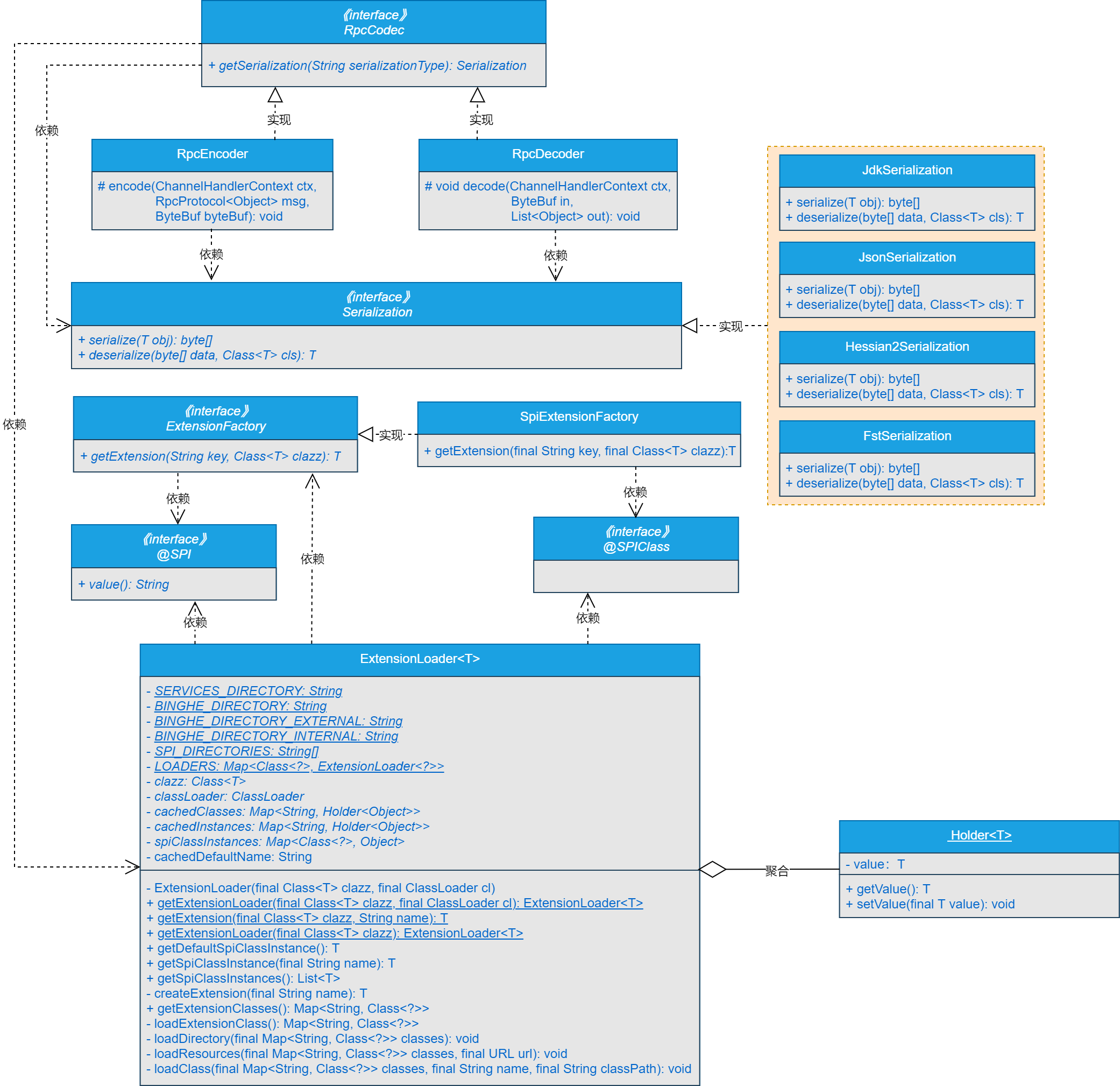
# 心类实现关系
基于SPI再次扩展FST的序列化与反序列化机制的核心类关系如图29-2所示。
# 查看完整文章
加入冰河技术 (opens new window)知识星球,解锁完整技术文章与完整代码
