# SA实战 ·《SpringCloud Alibaba实战》第16章-链路追踪:项目整合Sleuth实现链路追踪
作者:冰河
星球:http://m6z.cn/6aeFbs (opens new window)
博客:https://binghe.site (opens new window)
文章汇总:https://binghe.site/md/all/all.html (opens new window)
大家好,我是冰河~~
一不小心《SpringCloud Alibaba实战 (opens new window)》专栏都更新到第16章了,再不上车就跟不上了,小伙伴们快跟上啊!
注意:本项目完整源码加入 冰河技术 (opens new window) 知识星球即可获取,文末有优惠券。
在《SpringCloud Alibaba实战 (opens new window)》专栏前面的文章中,我们实现了用户微服务、商品微服务和订单微服务之间的远程调用,并且实现了服务调用的负载均衡。也基于阿里开源的Sentinel实现了服务的限流与容错,并详细介绍了Sentinel的核心技术与配置规则。简单介绍了服务网关,并对SpringCloud Gateway的核心架构进行了简要说明,也在项目中整合了SpringCloud Gateway网关实现了通过网关访问后端微服务,同时,也基于SpringCloud Gateway整合Sentinel实现了网关的限流功能,详细介绍了SpringCloud Gateway网关的核心技术。
在链路追踪章节,我们开始简单介绍了分布式链路追踪技术与解决方案。
今天,正式进入链路追踪章节,本章,就正式在项目中整合Sleuth实现链路追踪。
# 本章总览
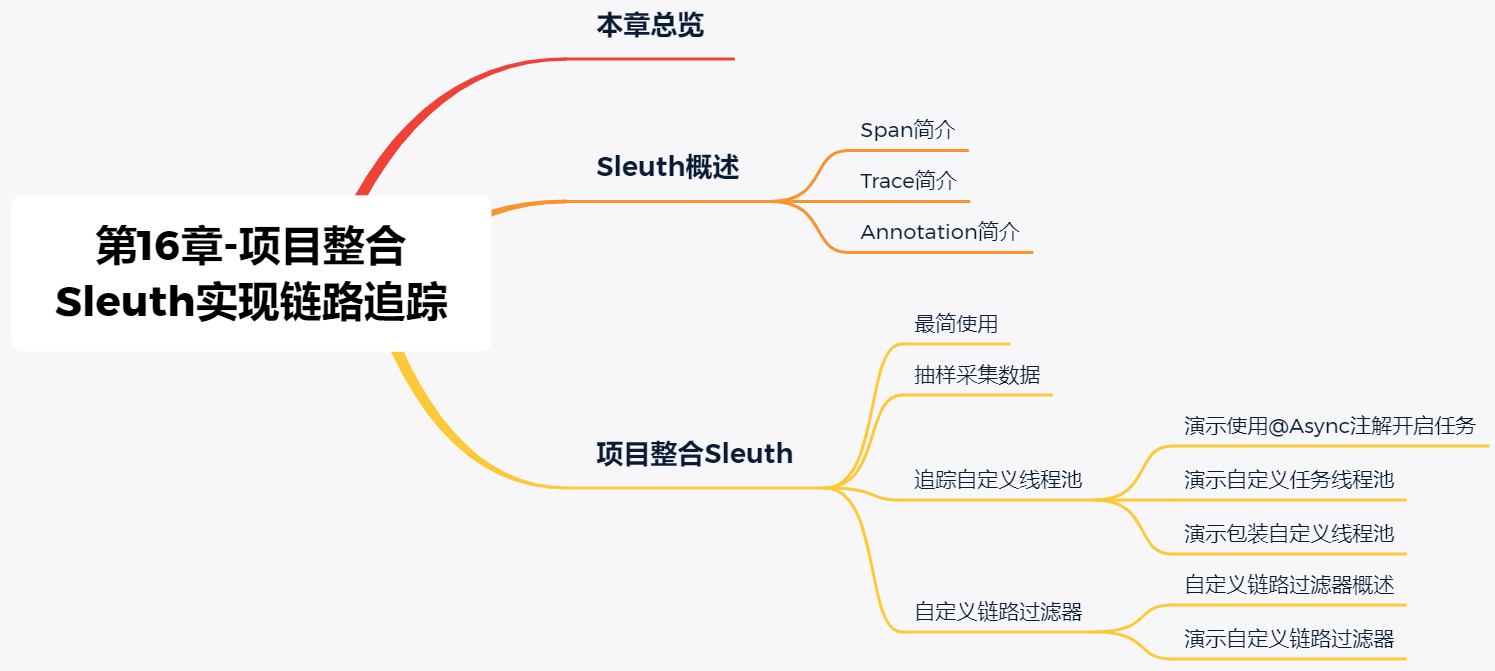
# Sleuth概述
Sleuth是SpringCloud中提供的一个分布式链路追踪组件,在设计上大量参考并借用了Google Dapper的设计。Sleuth中的核心术语如下。
# Span简介
Span代表了一组基本的工作单元。为了统计各处理单元的延迟,当请求到达各个服务组件的时候,通过一个唯一标识(SpanId)来标记它的开始、具体过程和结束。通过SpanId的开始和结束时间戳,就能统计这个Span的调用时间,除此之外,还可以获取如事件的名称。请求息等元数据。
总结:远程调用和 Span是一对一的关系,是分布式链路追踪中最基本的工作单元,每次发送一个远程调用服务就会产生一个 Span。Span Id 是一个 64 位的唯一 ID,通过计算 Span 的开始和结束时间,就可以统计每个服务调用所花费的时间。
# Trace简介
Trace主要由一组Trace Id相同的Span串联形成一个树状结构。为了实现请求跟踪,当请求到达分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的标识(即TraceId),同时在分布式系统内部流转的时候,框架始终保持传递这个唯一值,直到整个请求返回。此时就可以使用这个唯一标识将所有的请求串联起来,形成一条完整的请求链路。
总结:一个 Trace 可以对应多个 Span,Trace和Span是一对多的关系。Trace是由一系列 Span 组成的树状结构。Trace Id是一个64 位的唯一ID。每次用户端访问微服务系统的 API 接口,中间可能会调用多个微服务,每次调用都会产生一个新的Span,而多个Span组成了一个Trace。
# Annotation简介
Annotation记录了一段时间内的事件,内部使用的重要注解如下所示。
- cs(Client Send)客户端发出请求,标记整个请求的开始时间。
- sr(Server Received)服务端收到请求开始进行处理, sr- cs = 网络延迟(服务调用的时间)。
- ss(Server Send)服务端处理完毕准备将结果返回给客户端, ss - sr = 服务器上的请求处理时间。
- cr(Client Reveived)客户端收到服务端的响应,请求结束。 cr - cs = 请求的总时间。
总结:链路追踪系统定义了少量核心注解,用来定义一个请求的开始和结束,注意是微服务之间的请求,而不是从浏览器、APP、H5、小程序等发出的请求。
# 项目整合Sleuth
Sleuth提供了分布式链路追踪能力,如果需要使用Sleuth的链路追踪功能,需要在项目中集成Sleuth。
# 最简使用
(1)在每个微服务(用户微服务shop-user、商品微服务shop-product、订单微服务shop-order、网关服务shop-gateway)下的pom.xml文件中添加如下Sleuth的依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2
3
4
(2)将项目的application.yml文件备份成application-pre-filter.yml,并将application.yml文件的内容替换为application-sentinel.yml文件的内容,这一步是为了让整个项目集成Sentinel、SpringCloud Gateway和Nacos。application.yml替换后的文件内容如下所示。
server:
port: 10002
spring:
application:
name: server-gateway
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
sentinel:
transport:
port: 7777
dashboard: 127.0.0.1:8888
web-context-unify: false
eager: true
gateway:
globalcors:
cors-configurations:
'[/**]':
allowedOrigins: "*"
allowedMethods: "*"
allowCredentials: true
allowedHeaders: "*"
discovery:
locator:
enabled: true
route-id-prefix: gateway-
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
(3)分别启动Nacos、Sentinel、用户微服务shop-user,商品微服务shop-product,订单微服务shop-order和网关服务shop-gateway,在浏览器中输入链接localhost:10001/server-order/order/submit_order?userId=1001&productId=1001&count=1,如下所示。

(4)分别查看用户微服务shop-user,商品微服务shop-product,订单微服务shop-order和网关服务shop-gateway的控制台输出,每个服务的控制台都输出了如下格式所示的信息。
[微服务名称,TraceID,SpanID,是否将结果输出到第三方平台]
具体如下所示。
- 用户微服务shop-user
[server-user,03fef3d312450828,76b298dba54ec579,true]
- 商品微服务shop-product
[server-product,03fef3d312450828,41ac8836d2df4eec,true]
[server-product,03fef3d312450828,6b7b3662d63372bf,true]
2
- 订单微服务shop-order
[server-order,03fef3d312450828,cbd935d57cae84f9,true]
- 网关服务shop-gateway
[server-gateway,03fef3d312450828,03fef3d312450828,true]
可以看到,每个服务都打印出了链路追踪的日志信息,说明引入Sleuth的依赖后,就可以在命令行查看链路追踪情况。
# 抽样采集数据
Sleuth支持抽样采集数据。尤其是在高并发场景下,如果采集所有的数据,那么采集的数据量就太大了,非常耗费系统的性能。通常的做法是可以减少一部分数据量,特别是对于采用Http方式去发送采集数据,能够提升很大的性能。
Sleuth可以采用如下方式配置抽样采集数据。
spring:
sleuth:
sampler:
probability: 1.0
2
3
4
# 追踪自定义线程池
Sleuth支持对异步任务的链路追踪,在项目中使用@Async注解开启一个异步任务后,Sleuth会为异步任务重新生成一个Span。但是如果使用了自定义的异步任务线程池,则会导致Sleuth无法新创建一个Span,而是会重新生成Trace和Span。此时,需要使用Sleuth提供的LazyTraceExecutor类来包装下异步任务线程池,才能在异步任务调用链路中重新创建Span。
在服务中开启异步线程池任务,需要使用@EnableAsync。所以,在演示示例前,先在用户微服务shop-user的io.binghe.shop.UserStarter启动类上添加@EnableAsync注解,如下所示。
/**
* @author binghe
* @version 1.0.0
* @description 启动用户服的类
*/
@SpringBootApplication
@EnableTransactionManagement(proxyTargetClass = true)
@MapperScan(value = { "io.binghe.shop.user.mapper" })
@EnableDiscoveryClient
@EnableAsync
public class UserStarter {
public static void main(String[] args){
SpringApplication.run(UserStarter.class, args);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 演示使用@Async注解开启任务
(1)在用户微服务shop-user的io.binghe.shop.user.service.UserService接口中定义一个asyncMethod()方法,如下所示。
void asyncMethod();
(2)在用户微服务shop-user的io.binghe.shop.user.service.impl.UserServiceImpl类中实现asyncMethod()方法,并在asyncMethod()方法上添加@Async注解,如下所示。
@Async
@Override
public void asyncMethod() {
log.info("执行了异步任务...");
}
2
3
4
5
(3)在用户微服务shop-user的io.binghe.shop.user.controller.UserController类中新增asyncApi()方法,如下所示。
@GetMapping(value = "/async/api")
public String asyncApi() {
log.info("执行异步任务开始...");
userService.asyncMethod();
log.info("异步任务执行结束...");
return "asyncApi";
}
2
3
4
5
6
7
(4)分别启动用户微服务和网关服务,在浏览器中输入链接http://localhost:10001/server-user/user/async/api

(5)查看用户微服务与网关服务的控制台日志,分别存在如下日志。
- 用户微服务
[server-user,499d6c7128399ed0,a81bd920de0b07de,true]执行异步任务开始...
[server-user,499d6c7128399ed0,a81bd920de0b07de,true]异步任务执行结束...
[server-user,499d6c7128399ed0,e2f297d512f40bb8,true]执行了异步任务...
2
3
- 网关服务
[server-gateway,499d6c7128399ed0,499d6c7128399ed0,true]
可以看到Sleuth为异步任务重新生成了Span。
# 演示自定义任务线程池
在演示使用@Async注解开启任务的基础上继续演示自定义任务线程池,验证Sleuth是否为自定义线程池新创建了Span。
(1)在用户微服务shop-user中新建io.binghe.shop.user.config包,在包下创建ThreadPoolTaskExecutorConfig类,继承org.springframework.scheduling.annotation.AsyncConfigurerSupport类,用来自定义异步任务线程池,代码如下所示。
/**
* @author binghe
* @version 1.0.0
* @description Sleuth异步线程池配置
*/
@Configuration
@EnableAutoConfiguration
public class ThreadPoolTaskExecutorConfig extends AsyncConfigurerSupport {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2);
executor.setMaxPoolSize(5);
executor.setQueueCapacity(10);
executor.setThreadNamePrefix("trace-thread-");
executor.initialize();
return executor;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
(2)以debug的形式启动用户微服务和网关服务,并在io.binghe.shop.user.config.ThreadPoolTaskExecutorConfig#getAsyncExecutor()方法中打上断点,如下所示。

可以看到,项目启动后并没有进入io.binghe.shop.user.config.ThreadPoolTaskExecutorConfig#getAsyncExecutor()方法,说明项目启动时,并不会创建异步任务线程池。
(3)在浏览器中输入链接http://localhost:10001/server-user/user/async/api,此时可以看到程序已经执行到io.binghe.shop.user.config.ThreadPoolTaskExecutorConfig#getAsyncExecutor()方法的断点位置。
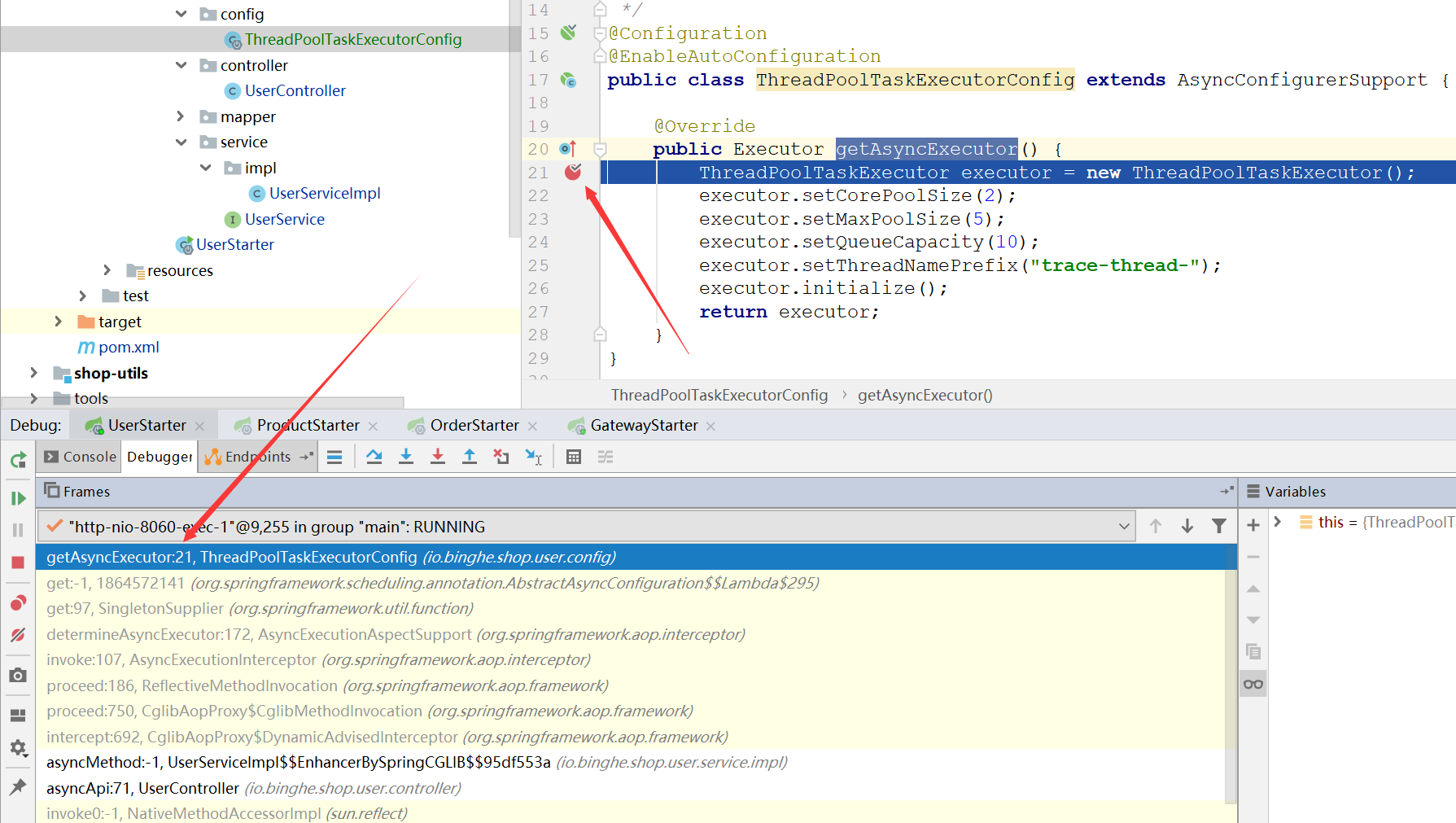
说明异步任务线程池是在调用了异步任务的时候创建的。
接下来,按F8跳过断点继续运行程序,可以看到浏览器上的显示结果如下。
(4)查看用户微服务与网关服务的控制台日志,分别存在如下日志。
- 用户微服务
[server-user,f89f2355ec3f9df1,4d679555674e96a4,true]执行异步任务开始...
[server-user,f89f2355ec3f9df1,4d679555674e96a4,true]异步任务执行结束...
[server-user,0ee48d47e58e2a42,0ee48d47e58e2a42,true]执行了异步任务...
2
3
- 网关服务
[server-gateway,f89f2355ec3f9df1,f89f2355ec3f9df1,true]
可以看到,使用自定义异步任务线程池时,在用户微服务中在执行异步任务时,重新生成了Trace和Span。
注意对比用户微服务中输出的三条日志信息,最后一条日志信息的TraceID和SpanID与前两条日志都不同。
# 演示包装自定义线程池
在自定义任务线程池的基础上继续演示包装自定义线程池,验证Sleuth是否为包装后的自定义线程池新创建了Span。
(1)在用户微服务shop-user的io.binghe.shop.user.config.ThreadPoolTaskExecutorConfig类中注入BeanFactory,并在getAsyncExecutor()方法中使用org.springframework.cloud.sleuth.instrument.async.LazyTraceExecutor()来包装返回的异步任务线程池,修改后的io.binghe.shop.user.config.ThreadPoolTaskExecutorConfig类的代码如下所示。
/**
* @author binghe
* @version 1.0.0
* @description Sleuth异步线程池配置
*/
@Configuration
@EnableAutoConfiguration
public class ThreadPoolTaskExecutorConfig extends AsyncConfigurerSupport {
@Autowired
private BeanFactory beanFactory;
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2);
executor.setMaxPoolSize(5);
executor.setQueueCapacity(10);
executor.setThreadNamePrefix("trace-thread-");
executor.initialize();
return new LazyTraceExecutor(this.beanFactory, executor);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
(2)分别启动用户微服务和网关服务,在浏览器中输入链接http://localhost:10001/server-user/user/async/api
(3)查看用户微服务与网关服务的控制台日志,分别存在如下日志。
- 用户微服务
[server-user,157891cb90fddb65,0a278842776b1f01,true]执行异步任务开始...
[server-user,157891cb90fddb65,0a278842776b1f01,true]异步任务执行结束...
[server-user,157891cb90fddb65,1ba55fd3432b77ae,true]执行了异步任务...
2
3
- 网关服务
[server-gateway,157891cb90fddb65,157891cb90fddb65,true]
可以看到Sleuth为异步任务重新生成了Span。
综上说明:Sleuth支持对异步任务的链路追踪,在项目中使用@Async注解开启一个异步任务后,Sleuth会为异步任务重新生成一个Span。但是如果使用了自定义的异步任务线程池,则会导致Sleuth无法新创建一个Span,而是会重新生成Trace和Span。此时,需要使用Sleuth提供的LazyTraceExecutor类来包装下异步任务线程池,才能在异步任务调用链路中重新创建Span。
# 自定义链路过滤器
在Sleuth中存在链路过滤器,并且还支持自定义链路过滤器。
# 自定义链路过滤器概述
TracingFilter是Sleuth中负责处理请求和响应的组件,可以通过注册自定义的TracingFilter实例来实现一些扩展性的需求。
# 演示自定义链路过滤器
本案例演示通过过滤器验证只有HTTP或者HTTPS请求才能访问接口,并且在访问的链接不是静态文件时,将traceId放入HttpRequest中在服务端获取,并在响应结果中添加自定义Header,名称为SLEUTH-HEADER,值为traceId。
(1)在用户微服务shop-user中新建io.binghe.shop.user.filter包,并创建MyGenericFilter类,继承org.springframework.web.filter.GenericFilterBean类,代码如下所示。
/**
* @author binghe
* @version 1.0.0
* @description 链路过滤器
*/
@Component
@Order( Ordered.HIGHEST_PRECEDENCE + 6)
public class MyGenericFilter extends GenericFilterBean{
private Pattern skipPattern = Pattern.compile(SleuthWebProperties.DEFAULT_SKIP_PATTERN);
private final Tracer tracer;
public MyGenericFilter(Tracer tracer){
this.tracer = tracer;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
if (!(request instanceof HttpServletRequest) || !(response instanceof HttpServletResponse)){
throw new ServletException("只支持HTTP访问");
}
Span currentSpan = this.tracer.currentSpan();
if (currentSpan == null) {
chain.doFilter(request, response);
return;
}
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
HttpServletResponse httpServletResponse = ((HttpServletResponse) response);
boolean skipFlag = skipPattern.matcher(httpServletRequest.getRequestURI()).matches();
if (!skipFlag){
String traceId = currentSpan.context().traceIdString();
httpServletRequest.setAttribute("traceId", traceId);
httpServletResponse.addHeader("SLEUTH-HEADER", traceId);
}
chain.doFilter(httpServletRequest, httpServletResponse);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
(2)在用户微服务shop-user的io.binghe.shop.user.controller.UserController类中新建sleuthFilter()方法,在sleuthFilter()方法中获取并打印traceId,如下所示。
@GetMapping(value = "/sleuth/filter/api")
public String sleuthFilter(HttpServletRequest request) {
Object traceIdObj = request.getAttribute("traceId");
String traceId = traceIdObj == null ? "" : traceIdObj.toString();
log.info("获取到的traceId为: " + traceId);
return "sleuthFilter";
}
2
3
4
5
6
7
(3)分别启动用户微服务和网关服务,在浏览器中输入http://localhost:10001/server-user/user/sleuth/filter/api,如下所示。

查看用户微服务的控制台会输出如下信息。
获取到的traceId为: f63ae7702f6f4bba
查看浏览器的控制台,看到在响应的结果信息中新增了一个名称为SLEUTH-HEADER,值为f63ae7702f6f4bba的Header,如下所示。
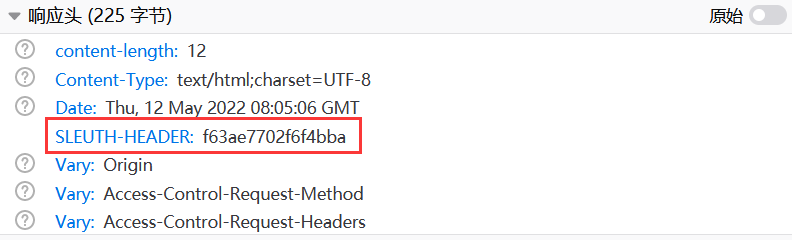
说明使用Sleuth的过滤器可以处理请求和响应信息,并且可以在Sleuth的过滤器中获取到TraceID。
好了,今天我们就到儿吧,限于篇幅,文中并未给出完整的案例源代码,想要完整源代码的小伙伴可加入【冰河技术】知识星球获取源码。也可以加我微信:hacker_binghe,一起交流技术。
另外,一不小心就写了16章了,小伙伴们你们再不上车就真的跟不上了!!!
# 星球服务
加入星球,你将获得:
1.项目学习:微服务入门必备的SpringCloud Alibaba实战项目、手写RPC项目—所有大厂都需要的项目【含上百个经典面试题】、深度解析Spring6核心技术—只要学习Java就必须深度掌握的框架【含数十个经典思考题】、Seckill秒杀系统项目—进大厂必备高并发、高性能和高可用技能。
2.框架源码:手写RPC项目—所有大厂都需要的项目【含上百个经典面试题】、深度解析Spring6核心技术—只要学习Java就必须深度掌握的框架【含数十个经典思考题】。
3.硬核技术:深入理解高并发系列(全册)、深入理解JVM系列(全册)、深入浅出Java设计模式(全册)、MySQL核心知识(全册)。
4.技术小册:深入理解高并发编程(第1版)、深入理解高并发编程(第2版)、从零开始手写RPC框架、SpringCloud Alibaba实战、冰河的渗透实战笔记、MySQL核心知识手册、Spring IOC核心技术、Nginx核心技术、面经手册等。
5.技术与就业指导:提供相关就业辅导和未来发展指引,冰河从初级程序员不断沉淀,成长,突破,一路成长为互联网资深技术专家,相信我的经历和经验对你有所帮助。
冰河的知识星球是一个简单、干净、纯粹交流技术的星球,不吹水,目前加入享5折优惠,价值远超门票。加入星球的用户,记得添加冰河微信:hacker_binghe,冰河拉你进星球专属VIP交流群。
# 星球重磅福利
跟冰河一起从根本上提升自己的技术能力,架构思维和设计思路,以及突破自身职场瓶颈,冰河特推出重大优惠活动,扫码领券进行星球,直接立减149元,相当于5折, 这已经是星球最大优惠力度!
领券加入星球,跟冰河一起学习《SpringCloud Alibaba实战》、《手撸RPC专栏》和《Spring6核心技术》,更有已经上新的《大规模分布式Seckill秒杀系统》,从零开始介绍原理、设计架构、手撸代码。后续更有硬核中间件项目和业务项目,而这些都是你升职加薪必备的基础技能。
100多元就能学这么多硬核技术、中间件项目和大厂秒杀系统,如果是我,我会买他个终身会员!
# 其他方式加入星球
- 链接 :打开链接 http://m6z.cn/6aeFbs (opens new window) 加入星球。
- 回复 :在公众号 冰河技术 回复 星球 领取优惠券加入星球。
特别提醒: 苹果用户进圈或续费,请加微信 hacker_binghe 扫二维码,或者去公众号 冰河技术 回复 星球 扫二维码加入星球。
# 星球规划
后续冰河还会在星球更新大规模中间件项目和深度剖析核心技术的专栏,目前已经规划的专栏如下所示。
# 中间件项目
- 《大规模分布式定时调度中间件项目实战(非Demo)》:全程手撸代码。
- 《大规模分布式IM(即时通讯)项目实战(非Demo)》:全程手撸代码。
- 《大规模分布式网关项目实战(非Demo)》:全程手撸代码。
- 《手写Redis》:全程手撸代码。
- 《手写JVM》全程手撸代码。
# 超硬核项目
- 《从零落地秒杀系统项目》:全程手撸代码,在阿里云实现压测(已上新)。
- 《大规模电商系统商品详情页项目》:全程手撸代码,在阿里云实现压测。
- 其他待规划的实战项目,小伙伴们也可以提一些自己想学的,想一起手撸的实战项目。。。
既然星球规划了这么多内容,那么肯定就会有小伙伴们提出疑问:这么多内容,能更新完吗?我的回答就是:一个个攻破呗,咱这星球干就干真实中间件项目,剖析硬核技术和项目,不做Demo。初衷就是能够让小伙伴们学到真正的核心技术,不再只是简单的做CRUD开发。所以,每个专栏都会是硬核内容,像《SpringCloud Alibaba实战》、《手撸RPC专栏》和《Spring6核心技术》就是很好的示例。后续的专栏只会比这些更加硬核,杜绝Demo开发。
小伙伴们跟着冰河认真学习,多动手,多思考,多分析,多总结,有问题及时在星球提问,相信在技术层面,都会有所提高。将学到的知识和技术及时运用到实际的工作当中,学以致用。星球中不少小伙伴都成为了公司的核心技术骨干,实现了升职加薪的目标。
# 联系冰河
# 加群交流
本群的宗旨是给大家提供一个良好的技术学习交流平台,所以杜绝一切广告!由于微信群人满 100 之后无法加入,请扫描下方二维码先添加作者 “冰河” 微信(hacker_binghe),备注:星球编号。

# 公众号
分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。内容在 冰河技术 微信公众号首发,强烈建议大家关注。

# 视频号
定期分享各种编程语言、开发技术、分布式与微服务架构、分布式数据库、分布式事务、云原生、大数据与云计算技术和渗透技术。另外,还会分享各种面试题和面试技巧。

# 星球
加入星球 冰河技术 (opens new window),可以获得本站点所有学习内容的指导与帮助。如果你遇到不能独立解决的问题,也可以添加冰河的微信:hacker_binghe, 我们一起沟通交流。另外,在星球中不只能学到实用的硬核技术,还能学习实战项目!
关注 冰河技术 (opens new window)公众号,回复 星球 可以获取入场优惠券。

