# 《并发设计模式》第50章-主仆模式-到底什么是主仆模式
作者:冰河
星球:http://m6z.cn/6aeFbs (opens new window)
博客:https://binghe.site (opens new window)
文章汇总:https://binghe.site/md/all/all.html (opens new window)
源码获取地址:https://t.zsxq.com/0dhvFs5oR (opens new window)
沉淀,成长,突破,帮助他人,成就自我。
- 本章难度:★★☆☆☆
- 本章重点:了解主仆模式的核心原理与使用场景,能够初步结合自身项目实际场景思考如何将主仆模式灵活应用到自身实际项目中。
大家好,我是冰河~~
主仆模式本质上就是一种分而治之的思想,最核心的思想就是将一个比较大的任务分解成若干个比较小的子任务,并且会由专门的工作线程来并行执行这些拆分后的子任务,得出子任务的分析结果后,再整合各个子任务的处理结果,形成最终的结果数据。
# 一、故事背景
正当小菜洗漱完毕要睡觉时,此时接到运维的电话说生产环境统计热点商品的性能很差。但是,经过小菜自己长时间的排查和定位问题,最终还是没能定位到问题。于是,第2天小菜找到老王说明了情况,老王看到代码后,分析出了产生问题的原因,并耐心的为小菜进行了讲解。并且小菜也得知了解决分析统计热点商品性能差的问题比较适合使用并发编程设计模式中的主仆模式。
# 二、主仆模式概述
在某些场景下,为了提高计算的效率,往往会将一个大任务拆分为若干个小的子任务,并且使用专门的工作线程来执行这些子任务,然后将这些子任务的处理结果整合成最终的数据处理结果,如图50-1所示。
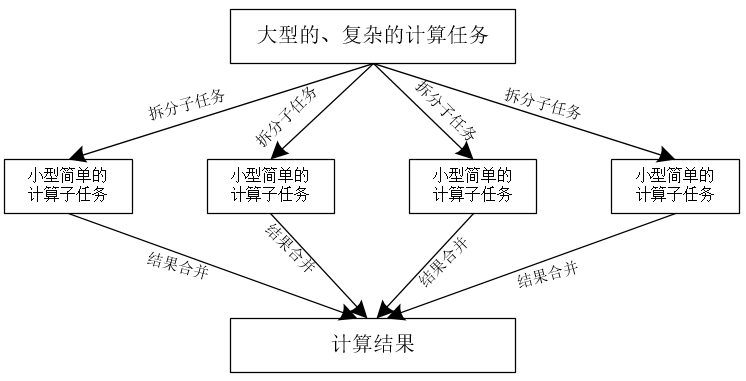
这点类似Hadoop中的MapReduce,Hadoop的MapReduce框架会将一个大型的、复杂的计算任务,拆分成多个小型的、简单的计算子任务,每个子任务在框架中都是高度并行计算的,之后MapReduce框架将各个计算子任务的计算结果进行合并,得出最终的计算结果。
每个子任务在MapReduce内部都是高度并行计算的,子任务的高度并行化,极大的提高了Hadoop处理海量数据的性能。MapReduce并行计算模型如图50-2所示。
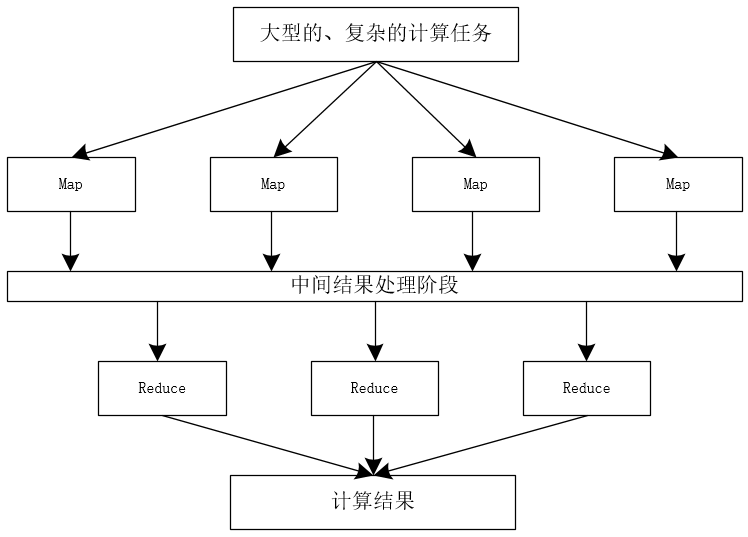
MapReduce框架将一个大型的、复杂的计算任务拆分为多个小的、简单的计算任务交由多个map并行计算,每个map的计算结果由中间结果处理阶段的处理后,输入reduce阶段,reduce阶段将输入的数据,进行合并处理,输出最终的计算结果。
同时,用户无需关心MapReduce底层各节点直接的通信机制与通信过程,只需简单的编写map()函数和reduce()函数即可开发Hadoop MapReduce程序。
可以看到,Hadoop的MapReduce并行计算与并发编程中的主仆模式非常相似。同时,对于主仆模式来说,对于任务的分解、子任务结果的合并以及工作者线程的管理细节都应该对外不可见,以简化代码的开发与维护。
# 三、主仆模式类图
主仆模式由一个主协调线程和若干个工作线程组成,整体类图也比较简单,如图50-3所示。
# 查看全文
加入冰河技术 (opens new window)知识星球,解锁完整技术文章与完整代码
